 SundayHK
SundayHK
一、MHA介绍
1.1 MHA介绍
MHA为MySQL主从复制架构提供了自动故障切换功能。MHA在监控到master节点故障时,会提升其中拥有最新数据的slave节点成为新的master节点,在这个期间,MHA会通过其他从节点获取额外信息来避免一致性方面的问题,从而在最大程度上保证数据的一致性,以达到真正意义上的高可用,而且整个故障转移过程对应用程序完全透明。
此外,MHA 还提供了 master 节点的在线切换功能,即按需切换 master/slave 节点,大概0.5-2秒内即可完成。
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,例如一主二从。因为至少需要三台服务器,出于机器成本的考虑,淘宝也在该基础上进行了改造,目前淘宝的TMHA已经支持一主一从。
1.2 MHA的组成
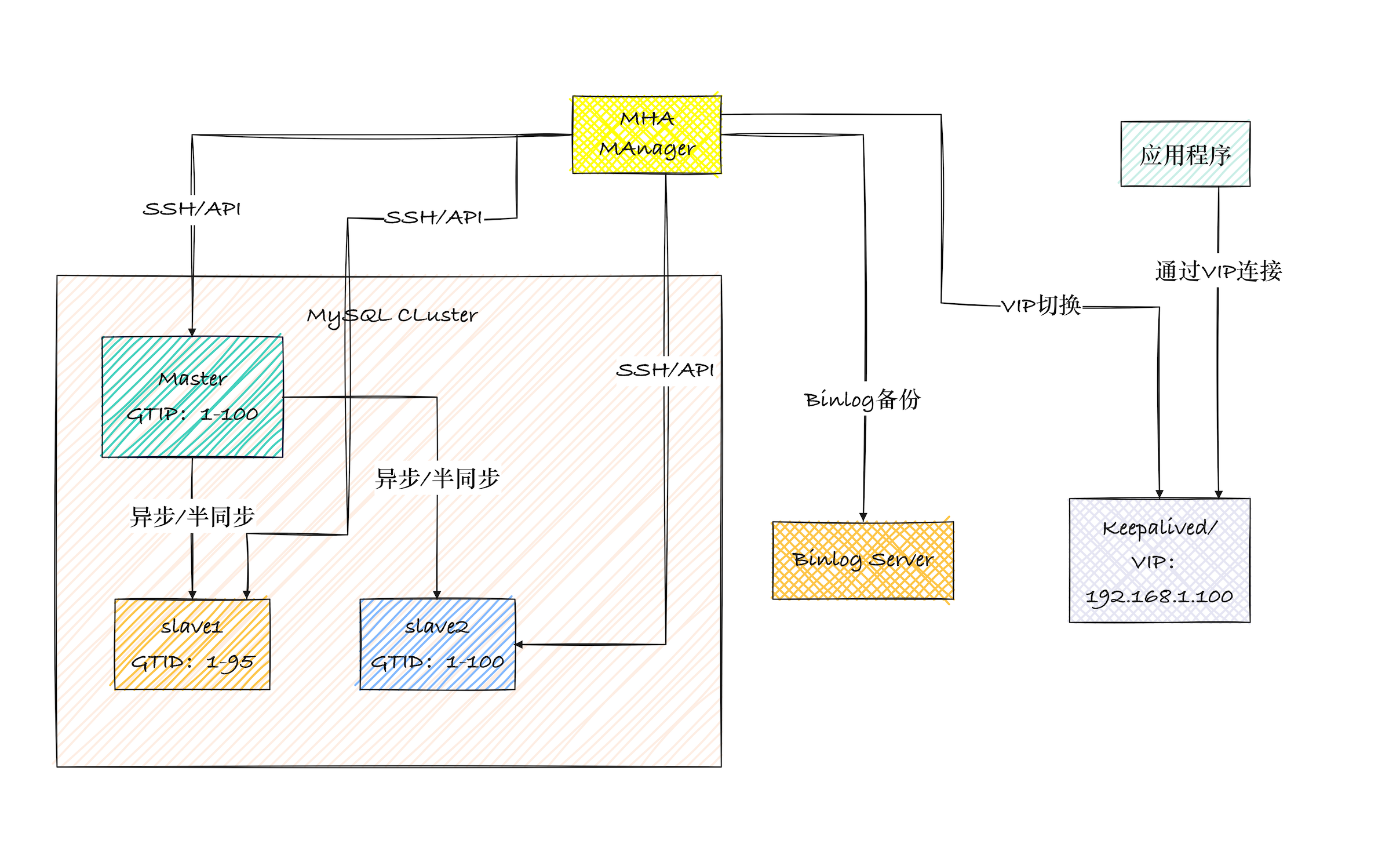
MHA由node和manager组成:
- MHA Node(数据节点):
相当于监控客户端,所有数据库机器都需要部署node
- MHA Manager(管理节点):
Manager相当于服务端,MHA Manager会定时探测集群中的master节点,当master出现故障时,他可以自动将最新数据的slave 提升为新的master,然后将所有其他的slave重新指向新的master(就算原主库恢复,也只能当从库了)。
通常单独部署在一台独立机器上管理多个master/slave集群,每个master/slave集群成为一个application,用来管理统筹整个集群。
Manager应该尽量避免部署在主库上,否则主机一挂则全挂,不仅主库完蛋了,负责自动迁移的Manager也完蛋了,也没人负责自动故障迁移了,导致架构不可用了。
可以考虑部署在某一个slave上,此时这台主机挂掉了,只是挂了一个slave,以及Manager,如果此时你不是倒了霉,(主库也挂了),那还不至于架构不可用。但有一点需要注意的是:如果Manager部署在slave上,那么该slave就无法被升级为主库;
每个复制组内部和 Manager 之间都需要ssh实现无密码互连,只有这样,在 Master 出故障时, Manager 才能顺利的连接进去,实现主从切换功能。
- binlog server(可选):存储主库binlog,用于补全差异数据
- keepalived/VIP:实现应用透明切换,无需修改连接配置。
1.3 MHA自动故障切换的步骤
- Manager会每隔三秒探测一次master主库
ping_interval 控制间隔时间;
ping_type 控制探测方式,SELECT(执行SELECT 1)和CONNECT(创建连接/断开连接)- 如果manager探测到master主库故障、无法访问
1、从其他node发起ssh连接,检查主库是否能够SSH上去;
2、从其他node发起mysql连接,检查MASTER库是否能够登陆;- 如果说所有node节点ssh连接、mysql连接均连接失败,则开始故障转移。
简单说:
1.找到数据最新的从库(通过对比relay-log,查看show slave status即可)
2.将最新的从库上的新数据同步到其他从库
3.提升一个从库为主库(一般情况提升数据最新的,二般情况提升我们指定的从库为主库)
4.通过原来主库的binlog补全新的主库数据
5.其他从库以新的主库为主做主从复制
| Phase 1 | Configuration Check Phase.. | 检查数据库版本 检查是否启用GTID 检查从库是否存活 检查配置文件的candidate |
|---|---|---|
| Phase 2 | Dead Master Shutdown Phase. | 该阶段会调用master_ip_failover脚本;去关闭所有Node的IO Thread 调用shutdown_script 强制关闭MASTER实例,防止应用程序来连接; |
| Phase 3 | Master Recovery Phase.. | |
| Phase 3.1 | Getting Latest Slaves Phase. | 检查所有节点,从show slave status中对比获取最新的binlog/position |
| Phase 3.2 | Saving Dead Master’s Binlog Phase.. | 如果老的Master可以SSH,上去获取BINLOG,从position到END位置,获取这段BINLOG(MASETER产生这段BINLOG,还未来得及发送给SLAVE)将这部分日志发送给Manager节点(manager_workdir位置); 如果故障Master无法SSH,则无法获取这段日志 |
| Phase 3.3 | Determining New Master Phase.. | 对比所有SLAVE,从最新SALVE中同步差异realy log给其他slave;最终确保所有SLAVE数据一致 |
| Phase 3.3 | New Master Diff Log Generation Phase.. | 确认新master 是否为最新slave,如果不是,则从最新slave获取差异日志; 将manager上获取的BINLOG日志发送给new master; |
| Phase 3.4 | Master Log Apply Phase.. | 对比新master的Exec_Master_Log_Pos和Read_Master_Log_Pos,判断恢复的位置; 在本地回放 3.3 Phase的差异日志; 获取新master的binlog和position; |
| Phase 4 | Slaves Recovery Phase.. | |
| Phase 4.1 | Starting Parallel Slave Diff Log Generation Phase. | 对每个SLAVE恢复:所有SLAVE和最新Slave做对比,如果position不一致,则生产差异日志 |
| Phase 4.2 | Starting Parallel Slave Log Apply Phase. | 每个SLAVE 应用差异日志; 执行CHANGE MASTER 挂在到新Master |
| Phase 5 | New master cleanup phase.. | reset slave all; |
1.4 MHA优点总结
- 自动故障检测与转移,通常在10~30秒
- MHA提供在线主库切换功能,能够安全的切换当前运行的主库到一个新的主库(通过将从库提升为主库),大概0.5秒~2秒可以完成。
- 很好的解决主库崩溃数据的一致性问题。
- 不需要对当前mysql环境做重大修改
- 不需要在现有的复制框架中添加额外的服务器,仅需要一个manager节点,而一个Manager能管理多套复制,所以能大大地节约服务器的数量;
- 性能优秀,可以工作在半同步和异步复制框架,支持gtid,当监控mysql状态时,仅需要每隔N秒向master发送ping包(默认3秒),所以对性能无影响。你可以理解为MHA的性能和简单的主从复制框架性能一样。
- 只要replication支持的存储引擎都支持MHA,不会局限于innodb
- 对于一般的keepalived高可用,当vip在一台机器上的时候,另一台机器是闲置的,而MHA中并无闲置主机。
二、部署MHA
2.1 环境准备
| 机器名称 | IP地址 | 角色 | 系统 | 备注 |
|---|---|---|---|---|
| mha-manager-160 | 192.168.77.160 | MHA Manager、MHA Node | CentOS7 | 用于监控管理 |
| mha-node-161 | 192.168.77.161 | MySQL Master、MHA Node | CentOS7 | 开启binlog、relay-log,关闭relay_log_purge |
| mha-node-162 | 192.168.77.162 | MySQL Slave、MHA Node | CentOS7 | 开启binlog、relay-log,关闭relay_log_purge、设置read_only=1 |
| mha-node-163 | 192.168.77.163 | MySQL Slave、MHA Node | CentOS7 | 开启binlog、relay-log,关闭relay_log_purge、设置read_only=1 |
MHA manager应该独立部署,不要混合部署。
1、配置hostname和hosts
hostnamectl set-hostname mha-manager-160
bash192.168.77.160 mha-manager-160
192.168.77.161 mha-node-161
192.168.77.162 mha-node-162
192.168.77.163 mha-node-1632、关闭防火墙
systemctl stop firewalld
systemctl disable firewalld3、禁用SELinux
setenforce 0
sed -i 's@^SELINUX=.*@SELINUX=disabled@' /etc/sysconfig/selinux4、关闭swap
# 临时关闭;关闭swap主要是为了性能考虑
swapoff -a
# 可以通过这个命令查看swap是否关闭了
free
# 永久关闭
sed -ri 's/.*swap.*/#&/' /etc/fstab2.2 MySQL主从部署
1)安装MySQL
# 添加mysql-server源
mkdir -p /opt/mysql-mha; cd /opt/mysql-mha
wget https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm
rpm -ivh mysql80-community-release-el7-3.noarch.rpm
# 解决报错如,Check that the correct key URLs are configured for this repository.
rpm --import http://repo.mysql.com/RPM-GPG-KEY-mysql-2022
# 更新yum缓存
yum makecache
# 使用yum查看MySQL的仓库,查看MySQL的版本
yum repolist all | grep mysql
# 安装yum-config-manager
yum -y install yum-utils
# 修改为需要的版本,即禁用yum存储库中mysql不需要的版本和开启需要的版本
yum-config-manager --disable mysql80-community
yum-config-manager --enable mysql57-community
# 先禁用本地的 MySQL 模块,要不然找不到mysql-community-server,默认mysql-server是8.0的版本
yum module disable mysql
# 开始安装mysql server和mysql client
yum install mysql-community-server mysql -y2)MySQL节点配置
修改配置文件
修改mysql的所有节点mysql的主配置文件 (/etc/my.cnf)
Master
skip-name-resolve
server-id=161
binlog_format=row
log-bin=mysql-bin
relay-log=mysql-relay-bin
log-slave-updates = 1
gtid-mode = on
enforce-gtid-consistency = 1Slave1
skip-name-resolve
server-id=162
binlog_format=row
log_bin=mysql-bin
relay-log=mysql-relay-bin
log-slave-updates = 0
gtid-mode = on
enforce-gtid-consistency = 1
relay_log_purge = 0Slave2
skip-name-resolve
server-id=163
binlog_format=row
log_bin=mysql-bin
relay-log=mysql-relay-bin
log-slave-updates = 0
gtid-mode = on
enforce-gtid-consistency = 1
relay_log_purge = 0启动服务
systemctl restart mysqld修改root密码
# 默认密码
grep 'temporary password' /var/log/mysqld.log
mysql -uroot -p
# 修改root密码
set global validate_password_policy=0; # 禁用密码复杂度
ALTER user 'root'@'localhost' IDENTIFIED BY 'Sunday123';3)配置MySQL 一主两从
Master节点配置复制权限
mysql -uroot -pSunday123
# 主从复制权限
set global validate_password_policy=0; # 禁用密码复杂度
grant replication slave on *.* to 'repl'@'192.168.77.%' identified by 'Sunday123';
flush privileges;在主库查看二进制状态
# 开启gtid后,数据库需要有事物执行,Executed_Gtid_Set才会有值
mysql> create database test;
Query OK, 1 row affected (0.00 sec)
mysql> show master status\G;
*************************** 1. row ***************************
File: mysql-bin.000007
Position: 313
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: d8ec2693-613f-11f0-9b36-005056afa147:1
1 row in set (0.00 sec)
ERROR:
No query specifiedslave1,slave2 执行
#master_auto_position=1 从库自动找同步点
mysql> change master to master_host='192.168.77.161', master_user='repl', master_password='Sunday123', master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
#两个slave节点都需要 Slave_IO_Running: Yes 和 Slave_SQL_Running: Yes
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.77.161
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000014
Read_Master_Log_Pos: 194
Relay_Log_File: mysql-relay-bin.000009
Relay_Log_Pos: 407
Relay_Master_Log_File: mysql-bin.000014
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 194
Relay_Log_Space: 1313
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 161
Master_UUID: d8ec2693-613f-11f0-9b36-005056afa147
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: d8ec2693-613f-11f0-9b36-005056afa147:1-3
Executed_Gtid_Set: d8ec2693-613f-11f0-9b36-005056afa147:1-3
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.01 sec)2.3 MHA部署
3、安装MHA Node软件
所有节点操作,含mha-manager节点
yum install -y epel-release
yum install -y perl perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager
wget https://github.com/yoshinorim/mha4mysql-node/releases/download/v0.58/mha4mysql-node-0.58-0.el7.centos.noarch.rpm
rpm -ivh mha4mysql-node-0.58-0.el7.centos.noarch.rpm4、安装MHA Manager
仅mha-manager-160节点
安装mha manager
wget https://github.com/yoshinorim/mha4mysql-manager/releases/download/v0.58/mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
# yum install mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
rpm -ivh mha4mysql-manager-0.58-0.el7.centos.noarch.rpm[root@mha-manager-160 ~]# ls -l /usr/bin/masterha*
-rwxr-xr-x. 1 root root 1995 Mar 22 2018 /usr/bin/masterha_check_repl
-rwxr-xr-x. 1 root root 1779 Mar 22 2018 /usr/bin/masterha_check_ssh
-rwxr-xr-x. 1 root root 1865 Mar 22 2018 /usr/bin/masterha_check_status
-rwxr-xr-x. 1 root root 3201 Mar 22 2018 /usr/bin/masterha_conf_host
-rwxr-xr-x. 1 root root 2517 Mar 22 2018 /usr/bin/masterha_manager
-rwxr-xr-x. 1 root root 2165 Mar 22 2018 /usr/bin/masterha_master_monitor
-rwxr-xr-x. 1 root root 2373 Mar 22 2018 /usr/bin/masterha_master_switch
-rwxr-xr-x. 1 root root 5172 Mar 22 2018 /usr/bin/masterha_secondary_check
-rwxr-xr-x. 1 root root 1739 Mar 22 2018 /usr/bin/masterha_stop2.4 配置MHA manager
1)MySQL MHA权限
set global validate_password_policy=0;
grant all on *.* to 'mha'@'192.168.77.%' identified by 'Sunday123';
flush privileges;- MHA对MySQL复制环境有特殊要求,例如各节点都需要开启二进制日志及中继日志,各个"slave"节点必须显式启用read-only属性,并关闭relay_log_purge功能。
# 1、在从库上进行操作
# 设置只读,不要添加配置文件,因为从库以后可能变成主库
mysql> set global read_only=1;
# 2、在所有库上都进行操作
# 关闭MySQL自动清除relaylog的功能
mysql> set global relay_log_purge = 0;
# 编辑配置文件
[root@mha-node-162 ~]## vim /etc/my.cnf
[mysqld]
# 禁用自动删除relay log永久生效
relay_log_purge = 02)配置互信
ssh-keygen
ssh-copy-id mha-manager-160
ssh-copy-id mha-node-161
ssh-copy-id mha-node-161
ssh-copy-id mha-node-161
scp ~/.ssh/id_rsa.* root@mha-manager-160
scp ~/.ssh/id_rsa.* root@mha-node-161
scp ~/.ssh/id_rsa.* root@mha-node-162
scp ~/.ssh/id_rsa.* root@mha-node-1633) MHA配置文件
[root@manager ~]# mkdir -p /data/mha/app1
[root@mha-manager-160 ~]# vim /data/mha/app1.cnf可以管理多套集群,后续如app2
[server default]
#日志存放路径
manager_log=/data/mha/manager.log
#定义工作目录位置
manager_workdir=/data/mha/app1
#binlog目录(若路径不一样,可以将配置写到相应的server下面)
master_binlog_dir=/var/lib/mysql
#设置ssh的登录用户名
ssh_user=root
#如果端口修改不是22的话,需要加参数,不建议改ssh端口
#否则后续如负责VIP漂移的perl脚本也都得改,很麻烦
ssh_port=22
#管理用户
user=mha
password=Sunday123
#复制用户
repl_user=repl
repl_password=Sunday123
#检测主库心跳的间隔时间
ping_interval=1
#设置自动failover时的切换脚本
master_ip_failover_script=/data/mha/master_ip_failover
#设置手动failover时的切换脚本 暂不启用
# master_ip_online_change_script=/data/mha/master_ip_online_change
[server1]
hostname=192.168.77.161
port=3306
ssh_user=root
candidate_master=1
check_repl_delay=0
[server2]
hostname=192.168.77.162
port=3306
ssh_user=root
candidate_master=1
check_repl_delay=0
[server3]
hostname=192.168.77.163
port=3306
ssh_user=root
candidate_master=1
check_repl_delay=0设置了以下两个参数,则该从库成为候选主库,优先级最高
-
candidate_master=1
设置为候选master,设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个从库不是集群中最新的slave,no_master=1正好相反 -
check_repl_delay=0
不管优先级高的备选库,数据延时多久都要往那切默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
选择哪个主机作为主节点
如果主机满足上述条件,则根据以下规则确定新的主服务器:
如果在某些主机上candicate_master = 1,则将优先考虑它们
如果其中一些是最新的(接收到最新二进制日志事件的从站),则该主机将被选作新的主站
*如果最新是多个主机,则主主机将由“配置文件中按节名称的顺序”确定。如果您具有server1,server2和server3部分,并且server1和server3均为候选人主控者和最新者,则将选择server1作为新的主控者。
如果没有任何服务器设置candicate_master = 1参数,
则最新的从属服务器将成为新的主服务器。如果最新是多个从站,则将应用“按节命名”规则。
*如果最新的从站都不是新的主站,则非最新的从站之一将是新的主站。按节命名规则也将在此处应用。
两个参数使用场景
- 多地多中心,设置本地节点为高权重
- 在有半同步复制的环境中,设置半同步复制节点为高权重
- 你觉着哪个机器适合做主节点,配置较高的 、性能较好的
4) 故障转移IP切换配置
编写master_ip_failover脚本
[root@mha-manager-160 ~]# vim /data/mha/master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
use MHA::DBHelper;
my (
$command, $ssh_user, $orig_master_host,
$orig_master_ip, $orig_master_port, $new_master_host,
$new_master_ip, $new_master_port, $new_master_user,
$new_master_password
);
# 修改下面4行
my $vip = '192.168.77.200/24'; # 修改VIP
my $key = '1';
my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip"; # 修改网卡接口名
my $ssh_stop_vip = "/sbin/ifconfig ens33:$key down";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
'new_master_user=s' => \$new_master_user,
'new_master_password=s' => \$new_master_password,
);
exit &main();
sub main {
print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
my $exit_code = 1;
eval {
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
sub stop_vip() {
return 0 unless ($ssh_user);
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}添加执行权限
[root@mha-manager-160 ~]# chmod +x /data/mha/master_ip_failover按需修改脚本中这些配置
my $vip = '192.168.77.200/24'; # 修改VIP
my $key = '1';
my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip"; # 修改网卡接口名
my $ssh_stop_vip = "/sbin/ifconfig ens33:$key down";在MySQL主节点手动配置VIP
[root@mha-manager-160 ~]# ifconfig ens192:1 192.168.77.200/24 up
[root@mha-manager-160 ~]# ifconfig
ens192: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.77.160 netmask 255.255.255.0 broadcast 192.168.77.255
inet6 fe80::290d:dfdb:c937:702f prefixlen 64 scopeid 0x20<link>
ether 00:50:56:af:8c:d3 txqueuelen 1000 (Ethernet)
RX packets 11568 bytes 1274689 (1.2 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8781 bytes 1026680 (1002.6 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens192:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.77.200 netmask 255.255.255.0 broadcast 192.168.77.255
ether 00:50:56:af:8c:d3 txqueuelen 1000 (Ethernet)2.5 检查MHA配置状态
MHA配置检查主要检查:SSH节点互信和主从复制状态。
STEP1:SSH节点互信检查
[root@mha-manager-160 ~]# masterha_check_ssh --conf=/data/mha/app1.cnf
Tue Jul 15 22:47:48 2025 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Tue Jul 15 22:47:48 2025 - [info] Reading application default configuration from /data/mha/app1.cnf..
Tue Jul 15 22:47:48 2025 - [info] Reading server configuration from /data/mha/app1.cnf..
Tue Jul 15 22:47:48 2025 - [info] Starting SSH connection tests..
Tue Jul 15 22:47:50 2025 - [debug]
Tue Jul 15 22:47:48 2025 - [debug] Connecting via SSH from root@192.168.77.161(192.168.77.161:22) to root@192.168.77.162(192.168.77.162:22)..
Tue Jul 15 22:47:49 2025 - [debug] ok.
Tue Jul 15 22:47:49 2025 - [debug] Connecting via SSH from root@192.168.77.161(192.168.77.161:22) to root@192.168.77.163(192.168.77.163:22)..
Tue Jul 15 22:47:50 2025 - [debug] ok.
Tue Jul 15 22:47:51 2025 - [debug]
Tue Jul 15 22:47:48 2025 - [debug] Connecting via SSH from root@192.168.77.162(192.168.77.162:22) to root@192.168.77.161(192.168.77.161:22)..
Tue Jul 15 22:47:50 2025 - [debug] ok.
Tue Jul 15 22:47:50 2025 - [debug] Connecting via SSH from root@192.168.77.162(192.168.77.162:22) to root@192.168.77.163(192.168.77.163:22)..
Tue Jul 15 22:47:51 2025 - [debug] ok.
Tue Jul 15 22:47:52 2025 - [debug]
Tue Jul 15 22:47:49 2025 - [debug] Connecting via SSH from root@192.168.77.163(192.168.77.163:22) to root@192.168.77.161(192.168.77.161:22)..
Tue Jul 15 22:47:50 2025 - [debug] ok.
Tue Jul 15 22:47:50 2025 - [debug] Connecting via SSH from root@192.168.77.163(192.168.77.163:22) to root@192.168.77.162(192.168.77.162:22)..
Tue Jul 15 22:47:51 2025 - [debug] ok.
Tue Jul 15 22:47:52 2025 - [info] All SSH connection tests passed successfully.
如果最后返回“successfully”字样,则说明SSH节点互信没有问题。
STEP2:主从复制状态检查
[root@mha-manager-160 ~]# masterha_check_repl --conf=/data/mha/app1.cnf
Tue Jul 15 23:09:25 2025 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Tue Jul 15 23:09:25 2025 - [info] Reading application default configuration from /data/mha/app1.cnf..
Tue Jul 15 23:09:25 2025 - [info] Reading server configuration from /data/mha/app1.cnf..
Tue Jul 15 23:09:25 2025 - [info] MHA::MasterMonitor version 0.58.
Tue Jul 15 23:09:26 2025 - [info] GTID failover mode = 1
Tue Jul 15 23:09:26 2025 - [info] Dead Servers:
Tue Jul 15 23:09:26 2025 - [info] Alive Servers:
Tue Jul 15 23:09:26 2025 - [info] 192.168.77.161(192.168.77.161:3306)
Tue Jul 15 23:09:26 2025 - [info] 192.168.77.162(192.168.77.162:3306)
Tue Jul 15 23:09:26 2025 - [info] 192.168.77.163(192.168.77.163:3306)
Tue Jul 15 23:09:26 2025 - [info] Alive Slaves:
Tue Jul 15 23:09:26 2025 - [info] 192.168.77.162(192.168.77.162:3306) Version=5.7.24-log (oldest major version between slaves) log-bin:enabled
Tue Jul 15 23:09:26 2025 - [info] GTID ON
Tue Jul 15 23:09:26 2025 - [info] Replicating from 192.168.77.161(192.168.77.161:3306)
Tue Jul 15 23:09:26 2025 - [info] Primary candidate for the new Master (candidate_master is set)
Tue Jul 15 23:09:26 2025 - [info] 192.168.77.163(192.168.77.163:3306) Version=5.7.24-log (oldest major version between slaves) log-bin:enabled
Tue Jul 15 23:09:26 2025 - [info] GTID ON
Tue Jul 15 23:09:26 2025 - [info] Replicating from 192.168.77.161(192.168.77.161:3306)
Tue Jul 15 23:09:26 2025 - [info] Primary candidate for the new Master (candidate_master is set)
Tue Jul 15 23:09:26 2025 - [info] Current Alive Master: 192.168.77.161(192.168.77.161:3306)
Tue Jul 15 23:09:26 2025 - [info] Checking slave configurations..
Tue Jul 15 23:09:26 2025 - [info] Checking replication filtering settings..
Tue Jul 15 23:09:26 2025 - [info] binlog_do_db= , binlog_ignore_db=
Tue Jul 15 23:09:26 2025 - [info] Replication filtering check ok.
Tue Jul 15 23:09:26 2025 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking.
Tue Jul 15 23:09:26 2025 - [info] Checking SSH publickey authentication settings on the current master..
Tue Jul 15 23:09:27 2025 - [info] HealthCheck: SSH to 192.168.77.161 is reachable.
Tue Jul 15 23:09:27 2025 - [info]
192.168.77.161(192.168.77.161:3306) (current master)
+--192.168.77.162(192.168.77.162:3306)
+--192.168.77.163(192.168.77.163:3306)
Tue Jul 15 23:09:27 2025 - [info] Checking replication health on 192.168.77.162..
Tue Jul 15 23:09:27 2025 - [info] ok.
Tue Jul 15 23:09:27 2025 - [info] Checking replication health on 192.168.77.163..
Tue Jul 15 23:09:27 2025 - [info] ok.
Tue Jul 15 23:09:27 2025 - [info] Checking master_ip_failover_script status:
Tue Jul 15 23:09:27 2025 - [info] /data/mha/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.77.161 --orig_master_ip=192.168.77.161 --orig_master_port=3306
IN SCRIPT TEST====/sbin/ifconfig ens192:1 down==/sbin/ifconfig ens192:1 192.168.77.200/24===
Checking the Status of the script.. OK
Tue Jul 15 23:09:27 2025 - [info] OK.
Tue Jul 15 23:09:27 2025 - [warning] shutdown_script is not defined.
Tue Jul 15 23:09:27 2025 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.如果最后出现“OK”,则说明主从复制正常。
MHA Manager相关脚本说明
masterha_check_repl: 检查MySQL复制运行情况
masterha_check_ssh:检查MHA与MySQL节点之间的ssh互信
masterha_check_status:检查masterha_manager的运行状态
masterha_manager:启动MHA Manager
masterha_stop:停止MHA Manager
masterha_master_switch :用于手动failover和手动主节点切换
masterha_secondary_check :通过MySQL从节点检查主节点状态
masterha_master_monitor:用于监控MySQL主节点,不常用
masterha_conf_host:一个帮助程序脚本,用于从配置文件中添加/删除主机条目,不常用
2.6 启动MHA
该启动方式,触发迁移则会自动退出
nohup masterha_manager --conf=/data/mha/app1.cnf --ignore_last_failover >> /data/mha/manager.log 2>&1 &
查看mha状态
[root@mha-manager-160 ~]# masterha_check_status --conf=/data/mha/app1.cnf
app1 (pid:3153) is running(0:PING_OK), master:192.168.77.161命令参数:
- --remove_dead_master_conf :添加此参数后,如果故障转移成功完成,则mha manager会从配置文件删除失效主服务器的部分。如果不加该参数,在切换时不会修改配置文件,此时如果启动masterha_manager,则masterha_manager将停止,并显示错误"there is a dead slave"
- --ignore_fail_on_start :默认情况下如果任何从属服务器发生故障,MHA Manager都不会启动故障转移,但是某些情况下,你可能希望进行故障转移。则可以在mha配置文件的节点配置部分添加ignore_fail=1,在masterha_manager添加该参数,及时这些服务器发生故障,MHA也会进行故障转移
- --ignore_last_failover :如果先前的故障转移失败,则8小时内不能再次启动故障转移,因为该问题可能再次发生。启动故障转移的步骤通常是手动删除
$manager_workdir/$(app_name).failover.error文件;通过设置--ignore_last_failover,无论最近的故障转移状态如何,MHA都会进行故障转移 - --last_failover_minute = 分钟 :如果故障转移是最近完成的(默认8小时),则mha manager不会进行故障转移,因为很可能通过故障转移无法解决问题。此参数可以用来修改时间标准
2.7 故障模拟与恢复
停掉mysql master
[root@mha-node-161 ~]# systemctl stop mysqld查看日志可以看到192.168.77.162成为新master
[root@mha-manager-160 ~]# cat /data/mha/manager.log
----- Failover Report -----
app1: MySQL Master failover 192.168.77.161(192.168.77.161:3306) to 192.168.77.162(192.168.77.162:3306) succeeded
Master 192.168.77.161(192.168.77.161:3306) is down!
Check MHA Manager logs at mha-manager-160:/data/mha/manager.log for details.
Started automated(non-interactive) failover.
Invalidated master IP address on 192.168.77.161(192.168.77.161:3306)
Selected 192.168.77.162(192.168.77.162:3306) as a new master.
192.168.77.162(192.168.77.162:3306): OK: Applying all logs succeeded.
192.168.77.162(192.168.77.162:3306): OK: Activated master IP address.
192.168.77.163(192.168.77.163:3306): OK: Slave started, replicating from 192.168.77.162(192.168.77.162:3306)
192.168.77.162(192.168.77.162:3306): Resetting slave info succeeded.
Master failover to 192.168.77.162(192.168.77.162:3306) completed successfully.slave1
[root@mha-node-162 ~]# ifconfig | grep 192.168.77.200
inet 192.168.77.200 netmask 255.255.255.0 broadcast 192.168.77.255slave2的master已指向192.168.77.162
[root@mha-node-163 ~]# mysql -pSunday123
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.77.162
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000008
Read_Master_Log_Pos: 154
Relay_Log_File: mysql-relay-bin.000002
Relay_Log_Pos: 295
Relay_Master_Log_File: mysql-bin.000008
Slave_IO_Running: Yes
Slave_SQL_Running: Yes2.8 修复MHA故障的主库
故障master作用slave连接新master
[root@mha-node-161 ~]# systemctl start mysqld
[root@mha-node-161 ~]# mysql -pSunday123
mysql> change master to master_host='192.168.77.162', master_user='repl', master_password='Sunday123', master_auto_position=1;
Query OK, 0 rows affected, 2 warnings (0.02 sec)
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.77.162
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000008
Read_Master_Log_Pos: 154
Relay_Log_File: mysql-relay-bin.000002
Relay_Log_Pos: 367
Relay_Master_Log_File: mysql-bin.000008
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
再次启动MHA(故障迁移一次masterha_manager就结束了,所以要重新启动)
nohup masterha_manager --conf=/data/mha/app1.cnf --ignore_last_failover >> /data/mha/manager.log 2>&1 &检测MHA启动状态
masterha_check_status --conf=/data/mha/app1.cnf2.9 MHA手动切换配置
MHA配置启用master_ip_online_change_script
[root@mha-manager-160 ~]# vim /data/mha/app1.cnf
#设置手动failover时的切换脚本
master_ip_online_change_script=/data/mha/master_ip_online_change在线切换VIP配置脚本
[root@mha-manager-160 ~]# vim /data/mha/master_ip_online_change#!/usr/bin/env perl
# Copyright (C) 2011 DeNA Co.,Ltd.
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to the Free Software
# Foundation, Inc.,
# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
## Note: This is a sample script and is not complete. Modify the script based on your environment.
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
use MHA::DBHelper;
use MHA::NodeUtil;
use Time::HiRes qw( sleep gettimeofday tv_interval );
use Data::Dumper;
my $_tstart;
my $_running_interval = 0.1;
my (
$command, $orig_master_is_new_slave, $orig_master_host,
$orig_master_ip, $orig_master_port, $orig_master_user,
$orig_master_password, $orig_master_ssh_user, $new_master_host,
$new_master_ip, $new_master_port, $new_master_user,
$new_master_password, $new_master_ssh_user,
);
# 在每次配置时,修改下面5行即可
my $vip = '192.168.77.200/24';
my $key = '1';
my $ssh_start_vip = "/sbin/ifconfig ens192:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig ens192:$key down";
my $ssh_user = "root";
GetOptions(
'command=s' => \$command,
'orig_master_is_new_slave' => \$orig_master_is_new_slave,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'orig_master_user=s' => \$orig_master_user,
'orig_master_password=s' => \$orig_master_password,
'orig_master_ssh_user=s' => \$orig_master_ssh_user,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
'new_master_user=s' => \$new_master_user,
'new_master_password=s' => \$new_master_password,
'new_master_ssh_user=s' => \$new_master_ssh_user,
);
exit &main();
sub current_time_us {
my ( $sec, $microsec ) = gettimeofday();
my $curdate = localtime($sec);
return $curdate . " " . sprintf( "%06d", $microsec );
}
sub sleep_until {
my $elapsed = tv_interval($_tstart);
if ( $_running_interval > $elapsed ) {
sleep( $_running_interval - $elapsed );
}
}
sub get_threads_util {
my $dbh = shift;
my $my_connection_id = shift;
my $running_time_threshold = shift;
my $type = shift;
$running_time_threshold = 0 unless ($running_time_threshold);
$type = 0 unless ($type);
my @threads;
my $sth = $dbh->prepare("SHOW PROCESSLIST");
$sth->execute();
while ( my $ref = $sth->fetchrow_hashref() ) {
my $id = $ref->{Id};
my $user = $ref->{User};
my $host = $ref->{Host};
my $command = $ref->{Command};
my $state = $ref->{State};
my $query_time = $ref->{Time};
my $info = $ref->{Info};
$info =~ s/^\s*(.*?)\s*$/$1/ if defined($info);
next if ( $my_connection_id == $id );
next if ( defined($query_time) && $query_time < $running_time_threshold );
next if ( defined($command) && $command eq "Binlog Dump" );
next if ( defined($user) && $user eq "system user" );
next
if ( defined($command)
&& $command eq "Sleep"
&& defined($query_time)
&& $query_time >= 1 );
if ( $type >= 1 ) {
next if ( defined($command) && $command eq "Sleep" );
next if ( defined($command) && $command eq "Connect" );
}
if ( $type >= 2 ) {
next if ( defined($info) && $info =~ m/^select/i );
next if ( defined($info) && $info =~ m/^show/i );
}
push @threads, $ref;
}
return @threads;
}
sub main {
if ( $command eq "stop" ) {
## Gracefully killing connections on the current master
# 1. Set read_only= 1 on the new master
# 2. DROP USER so that no app user can establish new connections
# 3. Set read_only= 1 on the current master
# 4. Kill current queries
# * Any database access failure will result in script die.
my $exit_code = 1;
eval {
## Setting read_only=1 on the new master (to avoid accident)
my $new_master_handler = new MHA::DBHelper();
# args: hostname, port, user, password, raise_error(die_on_error)_or_not
$new_master_handler->connect( $new_master_ip, $new_master_port,
$new_master_user, $new_master_password, 1 );
print current_time_us() . " Set read_only on the new master.. ";
$new_master_handler->enable_read_only();
if ( $new_master_handler->is_read_only() ) {
print "ok.\n";
}
else {
die "Failed!\n";
}
$new_master_handler->disconnect();
# Connecting to the orig master, die if any database error happens
my $orig_master_handler = new MHA::DBHelper();
$orig_master_handler->connect( $orig_master_ip, $orig_master_port,
$orig_master_user, $orig_master_password, 1 );
## Drop application user so that nobody can connect. Disabling per-session binlog beforehand
$orig_master_handler->disable_log_bin_local();
print current_time_us() . " Drpping app user on the orig master..\n";
# FIXME_xxx_drop_app_user($orig_master_handler);
## Waiting for N * 100 milliseconds so that current connections can exit
my $time_until_read_only = 15;
$_tstart = [gettimeofday];
my @threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
while ( $time_until_read_only > 0 && $#threads >= 0 ) {
if ( $time_until_read_only % 5 == 0 ) {
printf
"%s Waiting all running %d threads are disconnected.. (max %d milliseconds)\n",
current_time_us(), $#threads + 1, $time_until_read_only * 100;
if ( $#threads < 5 ) {
print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump . "\n"
foreach (@threads);
}
}
sleep_until();
$_tstart = [gettimeofday];
$time_until_read_only--;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
}
## Setting read_only=1 on the current master so that nobody(except SUPER) can write
print current_time_us() . " Set read_only=1 on the orig master.. ";
$orig_master_handler->enable_read_only();
if ( $orig_master_handler->is_read_only() ) {
print "ok.\n";
}
else {
die "Failed!\n";
}
## Waiting for M * 100 milliseconds so that current update queries can complete
my $time_until_kill_threads = 5;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
while ( $time_until_kill_threads > 0 && $#threads >= 0 ) {
if ( $time_until_kill_threads % 5 == 0 ) {
printf
"%s Waiting all running %d queries are disconnected.. (max %d milliseconds)\n",
current_time_us(), $#threads + 1, $time_until_kill_threads * 100;
if ( $#threads < 5 ) {
print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump . "\n"
foreach (@threads);
}
}
sleep_until();
$_tstart = [gettimeofday];
$time_until_kill_threads--;
@threads = get_threads_util( $orig_master_handler->{dbh},
$orig_master_handler->{connection_id} );
}
## Terminating all threads
print current_time_us() . " Killing all application threads..\n";
$orig_master_handler->kill_threads(@threads) if ( $#threads >= 0 );
print current_time_us() . " done.\n";
$orig_master_handler->enable_log_bin_local();
$orig_master_handler->disconnect();
## After finishing the script, MHA executes FLUSH TABLES WITH READ LOCK
print "Disabling the VIP on old master: $orig_master_host \n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
## Activating master ip on the new master
# 1. Create app user with write privileges
# 2. Moving backup script if needed
# 3. Register new master's ip to the catalog database
# We don't return error even though activating updatable accounts/ip failed so that we don't interrupt slaves' recovery.
# If exit code is 0 or 10, MHA does not abort
my $exit_code = 10;
eval {
my $new_master_handler = new MHA::DBHelper();
# args: hostname, port, user, password, raise_error_or_not
$new_master_handler->connect( $new_master_ip, $new_master_port,
$new_master_user, $new_master_password, 1 );
#####################עzhu shi jin yong er jin zhi ri zhi ###########################
## Set disable log bin
#$new_master_handler->disable_log_bin_local();
#########################################
print current_time_us() . " Set read_only=0 on the new master.\n";
## Set read_only=0 on the new master
$new_master_handler->disable_read_only();
#################### zhu shi chuang jian yong hu , bing kai qi bin log
## Creating an app user on the new master
# print current_time_us() . " Creating app user on the new master..\n";
# FIXME_xxx_create_app_user($new_master_handler);
# $new_master_handler->enable_log_bin_local();
# $new_master_handler->disconnect();
#######################################################################
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
## Update master ip on the catalog database, etc
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
# do nothing
&start_vip();
exit 0;
}
else {
&usage();
exit 1;
}
}
# simple system call that enable the VIP on the new master
sub start_vip() {
`ssh $ssh_user\@$new_master_ip \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIP on the old_master
sub stop_vip() {
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_online_change --command=start|stop|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
die;
}修改
my $vip = '192.168.77.200/24';
my $key = '1';
my $ssh_start_vip = "/sbin/ifconfig ens192:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig ens192:$key down";
my $ssh_user = "root";chmod +x /data/mha/master_ip_online_change在线手动主从切换
# 先停掉mha
masterha_stop --conf=/data/mha/app1.cnf
# 将主库切换到192.168.77.163
masterha_master_switch --master_state=alive --conf=/data/mha/app1.cnf --new_master_host=192.168.77.163 --orig_master_is_new_slave[root@mha-manager-160 ~]# masterha_master_switch --master_state=alive --conf=/data/mha/app1.cnf --new_master_host=192.168.77.163 --orig_master_is_new_slave
Wed Jul 16 02:22:41 2025 - [info] MHA::MasterRotate version 0.58.
Wed Jul 16 02:22:41 2025 - [info] Starting online master switch..
Wed Jul 16 02:22:41 2025 - [info]
Wed Jul 16 02:22:41 2025 - [info] * Phase 1: Configuration Check Phase..
Wed Jul 16 02:22:41 2025 - [info]
Wed Jul 16 02:22:41 2025 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Wed Jul 16 02:22:41 2025 - [info] Reading application default configuration from /data/mha/app1.cnf..
Wed Jul 16 02:22:41 2025 - [info] Reading server configuration from /data/mha/app1.cnf..
Wed Jul 16 02:22:42 2025 - [info] GTID failover mode = 1
Wed Jul 16 02:22:42 2025 - [info] Current Alive Master: 192.168.77.161(192.168.77.161:3306)
Wed Jul 16 02:22:42 2025 - [info] Alive Slaves:
Wed Jul 16 02:22:42 2025 - [info] 192.168.77.162(192.168.77.162:3306) Version=5.7.24-log (oldest major version between slaves) log-bin:enabled
Wed Jul 16 02:22:42 2025 - [info] GTID ON
Wed Jul 16 02:22:42 2025 - [info] Replicating from 192.168.77.161(192.168.77.161:3306)
Wed Jul 16 02:22:42 2025 - [info] Primary candidate for the new Master (candidate_master is set)
Wed Jul 16 02:22:42 2025 - [info] 192.168.77.163(192.168.77.163:3306) Version=5.7.24-log (oldest major version between slaves) log-bin:enabled
Wed Jul 16 02:22:42 2025 - [info] GTID ON
Wed Jul 16 02:22:42 2025 - [info] Replicating from 192.168.77.161(192.168.77.161:3306)
Wed Jul 16 02:22:42 2025 - [info] Primary candidate for the new Master (candidate_master is set)
It is better to execute FLUSH NO_WRITE_TO_BINLOG TABLES on the master before switching. Is it ok to execute on 192.168.77.161(192.168.77.161:3306)? (YES/no): yes
Wed Jul 16 02:22:48 2025 - [info] Executing FLUSH NO_WRITE_TO_BINLOG TABLES. This may take long time..
Wed Jul 16 02:22:48 2025 - [info] ok.
Wed Jul 16 02:22:48 2025 - [info] Checking MHA is not monitoring or doing failover..
Wed Jul 16 02:22:48 2025 - [info] Checking replication health on 192.168.77.162..
Wed Jul 16 02:22:48 2025 - [info] ok.
Wed Jul 16 02:22:48 2025 - [info] Checking replication health on 192.168.77.163..
Wed Jul 16 02:22:48 2025 - [info] ok.
Wed Jul 16 02:22:48 2025 - [info] 192.168.77.163 can be new master.
Wed Jul 16 02:22:48 2025 - [info]
From:
192.168.77.161(192.168.77.161:3306) (current master)
+--192.168.77.162(192.168.77.162:3306)
+--192.168.77.163(192.168.77.163:3306)
To:
192.168.77.163(192.168.77.163:3306) (new master)
+--192.168.77.162(192.168.77.162:3306)
+--192.168.77.161(192.168.77.161:3306)
Starting master switch from 192.168.77.161(192.168.77.161:3306) to 192.168.77.163(192.168.77.163:3306)? (yes/NO): yes
Wed Jul 16 02:22:50 2025 - [info] Checking whether 192.168.77.163(192.168.77.163:3306) is ok for the new master..
Wed Jul 16 02:22:50 2025 - [info] ok.
Wed Jul 16 02:22:50 2025 - [info] 192.168.77.161(192.168.77.161:3306): SHOW SLAVE STATUS returned empty result. To check replication filtering rules, temporarily executing CHANGE MASTER to a dummy host.
Wed Jul 16 02:22:50 2025 - [info] 192.168.77.161(192.168.77.161:3306): Resetting slave pointing to the dummy host.
Wed Jul 16 02:22:50 2025 - [info] ** Phase 1: Configuration Check Phase completed.
Wed Jul 16 02:22:50 2025 - [info]
Wed Jul 16 02:22:50 2025 - [info] * Phase 2: Rejecting updates Phase..
Wed Jul 16 02:22:50 2025 - [info]
Wed Jul 16 02:22:50 2025 - [info] Executing master ip online change script to disable write on the current master:
Wed Jul 16 02:22:50 2025 - [info] /data/mha/master_ip_online_change --command=stop --orig_master_host=192.168.77.161 --orig_master_ip=192.168.77.161 --orig_master_port=3306 --orig_master_user='mha' --new_master_host=192.168.77.163 --new_master_ip=192.168.77.163 --new_master_port=3306 --new_master_user='mha' --orig_master_ssh_user=root --new_master_ssh_user=root --orig_master_is_new_slave --orig_master_password=xxx --new_master_password=xxx
Wed Jul 16 02:22:50 2025 351452 Set read_only on the new master.. ok.
Wed Jul 16 02:22:50 2025 355216 Drpping app user on the orig master..
Wed Jul 16 02:22:50 2025 355766 Waiting all running 2 threads are disconnected.. (max 1500 milliseconds)
{'Time' => '17','db' => undef,'Id' => '187','User' => 'repl','State' => 'Master has sent all binlog to slave; waiting for more updates','Command' => 'Binlog Dump GTID','Info' => undef,'Host' => '192.168.77.162:52406'}
{'Time' => '16','db' => undef,'Id' => '188','User' => 'repl','State' => 'Master has sent all binlog to slave; waiting for more updates','Command' => 'Binlog Dump GTID','Info' => undef,'Host' => '192.168.77.163:48588'}
Wed Jul 16 02:22:50 2025 857085 Waiting all running 2 threads are disconnected.. (max 1000 milliseconds)
{'Time' => '17','db' => undef,'Id' => '187','User' => 'repl','State' => 'Master has sent all binlog to slave; waiting for more updates','Command' => 'Binlog Dump GTID','Info' => undef,'Host' => '192.168.77.162:52406'}
{'Time' => '16','db' => undef,'Id' => '188','User' => 'repl','State' => 'Master has sent all binlog to slave; waiting for more updates','Command' => 'Binlog Dump GTID','Info' => undef,'Host' => '192.168.77.163:48588'}
Wed Jul 16 02:22:51 2025 357779 Waiting all running 2 threads are disconnected.. (max 500 milliseconds)
{'Time' => '18','db' => undef,'Id' => '187','User' => 'repl','State' => 'Master has sent all binlog to slave; waiting for more updates','Command' => 'Binlog Dump GTID','Info' => undef,'Host' => '192.168.77.162:52406'}
{'Time' => '17','db' => undef,'Id' => '188','User' => 'repl','State' => 'Master has sent all binlog to slave; waiting for more updates','Command' => 'Binlog Dump GTID','Info' => undef,'Host' => '192.168.77.163:48588'}
Wed Jul 16 02:22:51 2025 858319 Set read_only=1 on the orig master.. ok.
Wed Jul 16 02:22:51 2025 860214 Waiting all running 2 queries are disconnected.. (max 500 milliseconds)
{'Time' => '18','db' => undef,'Id' => '187','User' => 'repl','State' => 'Master has sent all binlog to slave; waiting for more updates','Command' => 'Binlog Dump GTID','Info' => undef,'Host' => '192.168.77.162:52406'}
{'Time' => '17','db' => undef,'Id' => '188','User' => 'repl','State' => 'Master has sent all binlog to slave; waiting for more updates','Command' => 'Binlog Dump GTID','Info' => undef,'Host' => '192.168.77.163:48588'}
Wed Jul 16 02:22:52 2025 359074 Killing all application threads..
Wed Jul 16 02:22:52 2025 360137 done.
Disabling the VIP on old master: 192.168.77.161
Wed Jul 16 02:22:53 2025 - [info] ok.
Wed Jul 16 02:22:53 2025 - [info] Locking all tables on the orig master to reject updates from everybody (including root):
Wed Jul 16 02:22:53 2025 - [info] Executing FLUSH TABLES WITH READ LOCK..
Wed Jul 16 02:22:53 2025 - [info] ok.
Wed Jul 16 02:22:53 2025 - [info] Orig master binlog:pos is mysql-bin.000015:194.
Wed Jul 16 02:22:53 2025 - [info] Waiting to execute all relay logs on 192.168.77.163(192.168.77.163:3306)..
Wed Jul 16 02:22:53 2025 - [info] master_pos_wait(mysql-bin.000015:194) completed on 192.168.77.163(192.168.77.163:3306). Executed 0 events.
Wed Jul 16 02:22:53 2025 - [info] done.
Wed Jul 16 02:22:53 2025 - [info] Getting new master's binlog name and position..
Wed Jul 16 02:22:53 2025 - [info] mysql-bin.000005:154
Wed Jul 16 02:22:53 2025 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.77.163', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='xxx';
Wed Jul 16 02:22:53 2025 - [info] Executing master ip online change script to allow write on the new master:
Wed Jul 16 02:22:53 2025 - [info] /data/mha/master_ip_online_change --command=start --orig_master_host=192.168.77.161 --orig_master_ip=192.168.77.161 --orig_master_port=3306 --orig_master_user='mha' --new_master_host=192.168.77.163 --new_master_ip=192.168.77.163 --new_master_port=3306 --new_master_user='mha' --orig_master_ssh_user=root --new_master_ssh_user=root --orig_master_is_new_slave --orig_master_password=xxx --new_master_password=xxx
Wed Jul 16 02:22:53 2025 193366 Set read_only=0 on the new master.
Enabling the VIP - 192.168.77.200/24 on the new master - 192.168.77.163
Wed Jul 16 02:22:53 2025 - [info] ok.
Wed Jul 16 02:22:53 2025 - [info]
Wed Jul 16 02:22:53 2025 - [info] * Switching slaves in parallel..
Wed Jul 16 02:22:53 2025 - [info]
Wed Jul 16 02:22:53 2025 - [info] -- Slave switch on host 192.168.77.162(192.168.77.162:3306) started, pid: 6276
Wed Jul 16 02:22:53 2025 - [info]
Wed Jul 16 02:22:54 2025 - [info] Log messages from 192.168.77.162 ...
Wed Jul 16 02:22:54 2025 - [info]
Wed Jul 16 02:22:53 2025 - [info] Waiting to execute all relay logs on 192.168.77.162(192.168.77.162:3306)..
Wed Jul 16 02:22:53 2025 - [info] master_pos_wait(mysql-bin.000015:194) completed on 192.168.77.162(192.168.77.162:3306). Executed 0 events.
Wed Jul 16 02:22:53 2025 - [info] done.
Wed Jul 16 02:22:53 2025 - [info] Resetting slave 192.168.77.162(192.168.77.162:3306) and starting replication from the new master 192.168.77.163(192.168.77.163:3306)..
Wed Jul 16 02:22:53 2025 - [info] Executed CHANGE MASTER.
Wed Jul 16 02:22:53 2025 - [info] Slave started.
Wed Jul 16 02:22:54 2025 - [info] End of log messages from 192.168.77.162 ...
Wed Jul 16 02:22:54 2025 - [info]
Wed Jul 16 02:22:54 2025 - [info] -- Slave switch on host 192.168.77.162(192.168.77.162:3306) succeeded.
Wed Jul 16 02:22:54 2025 - [info] Unlocking all tables on the orig master:
Wed Jul 16 02:22:54 2025 - [info] Executing UNLOCK TABLES..
Wed Jul 16 02:22:54 2025 - [info] ok.
Wed Jul 16 02:22:54 2025 - [info] Starting orig master as a new slave..
Wed Jul 16 02:22:54 2025 - [info] Resetting slave 192.168.77.161(192.168.77.161:3306) and starting replication from the new master 192.168.77.163(192.168.77.163:3306)..
Wed Jul 16 02:22:54 2025 - [info] Executed CHANGE MASTER.
Wed Jul 16 02:22:54 2025 - [info] Slave started.
Wed Jul 16 02:22:54 2025 - [info] All new slave servers switched successfully.
Wed Jul 16 02:22:54 2025 - [info]
Wed Jul 16 02:22:54 2025 - [info] * Phase 5: New master cleanup phase..
Wed Jul 16 02:22:54 2025 - [info]
Wed Jul 16 02:22:54 2025 - [info] 192.168.77.163: Resetting slave info succeeded.
Wed Jul 16 02:22:54 2025 - [info] Switching master to 192.168.77.163(192.168.77.163:3306) completed successfully.192.168.77.163 拿到vip了
[root@mha-node-163 ~]# ifconfig | grep 192
ens192: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.77.163 netmask 255.255.255.0 broadcast 192.168.77.255
ens192:1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.77.200 netmask 255.255.255.0 broadcast 192.168.77.255[root@mha-node-161 ~]# mysql -pSunday123
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.77.163
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000005
Read_Master_Log_Pos: 154
Relay_Log_File: mysql-relay-bin.000002
Relay_Log_Pos: 367
Relay_Master_Log_File: mysql-bin.000005
Slave_IO_Running: Yes
Slave_SQL_Running: Yes2.10 定期清理日志relay_log
在搭建MHA集群时,要求将所有MySQL节点的自动清除relay log功能关闭,因为在故障切换时,进行数据恢复的时候,可能会需要从节点的relaylog日志。
mysql> show variables like 'relay_log_purge';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| relay_log_purge | OFF |
+-----------------+-------+那么从节点的relaylog如何删除呢?mha node提供了一个purge_relay_logs脚本,专用于清理relaylog。
[root@mha-node-162 ~]# which purge_relay_logs
/usr/bin/purge_relay_logs工作原理如下:
- purge_relay_logs的功能
- 为relay日志创建硬链接(最小化批量删除大文件导致的性能问题)
- SET GLOBAL relay_log_purge=1; FLUSH LOGS; SET GLOBAL relay_log_purge=0;
- 删除relay log(rm –f /path/to/archive_dir/*)
在从节点上手动执行relaylog清理:
[root@mha-node-162 ~]# purge_relay_logs --user=root --host=localhost --password=Sunday123 --disable_relay_log_purge
2025-07-16 02:29:15: purge_relay_logs script started.
Opening /var/lib/mysql/mysql-relay-bin.000001 ..
Opening /var/lib/mysql/mysql-relay-bin.000002 ..
Executing SET GLOBAL relay_log_purge=1; FLUSH LOGS; sleeping a few seconds so that SQL thread can delete older relay log files (if it keeps up); SET GLOBAL relay_log_purge=0; .. ok.
2025-07-16 02:29:18: All relay log purging operations succeeded.在生产环境中需要设置crontab定时执行
[root@mha-node-162 ~]# crontab -e
# purge relay logs at 5am
0 5 * * * purge_relay_logs --user=root --host=localhost --password=Sunday123 --disable_relay_log_purge >> /tmp/mha_purge_relay_logs.log 2>&1三、binlogserver备份
如果主库断电或者断网,binlog如何保存? 可以为MHA配置binlogserver,实时保存binglog
3.1 前期准备
准备一台新的mysql实例(与主库板块一致),GTID必须开启。
然后改mysql主机就用于实时拉取主库的binlog,并不与主库同步,只是用来拉取主库的binlog,防止主库突然断电3.2 停止MHA
masterha_stop --conf=/data/mha/app1.cnf3.3 创建binlog存放目录并设置权限
mkdir -p /bak/binlog/
chown -R mysql.mysql /bak/binlog3.4 手动执行备份binlog
cd /bak/binlog
# 查看所有从库show slave status\G
mysqlbinlog -R --host=主库ip地址 --user=mha --password=Sunday123 --raw --stop-never mysql-bin.000005 &
# 注意:写成mysql-bin.000002则会从该文件开始拉取一直到最新的
mysqlbinlog -R --host=192.168.77.101 --user=mha --password=Sunday123 --raw --stop-never mysql-bin.000005 &...
[binlog1]
no_master=1
# binlogserver主机的ip地址
hostname=192.168.77.102
# 不能跟当前机器数据库的binlog存放目录一样
master_binlog_dir=/bak/binlog/mysql> flush logs; -- 看到binlogserver主机上/bak/binlog目录下新增日志nohup masterha_manager --conf=/data/mha/app1.cnf --ignore_last_failover < /dev/null > /data/mha/manager.log 2>&1 &四、MHA常用命令
#1、重置slave
stop slave;
reset slave;
#2、查看
SHOW SLAVE STATUS; #查看从库复制状态
SHOW MASTER STATUS; #查看当前binlog位点
SHOW SLAVE HOSTS; #查看从库列表
#3、重做slave指向主库
stop slave;
CHANGE MASTER TO MASTER_HOST='192.168.77.100', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='egon', MASTER_PASSWORD='123';
start slave;
#4、停止mha
masterha_stop --conf=/data/mha/app1.cnf
#5、查看ssh与主从状态
masterha_check_ssh --conf=/data/mha/app1.cnf
masterha_check_repl --conf=/data/mha/app1.cnf
#6、启动mha
nohup masterha_manager --conf=/data/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /data/mha/manager.log 2>&1 &
#7、查看mha状态
masterha_check_status --conf=/data/mha/app1.cnf


